中国科学院信息工程研究所第六研究室15篇论文被AAAI2025录用
中国科学院信息工程研究所第六研究室15篇论文被AAAI2025录用
AAAI 2025(AAAI Conference on Artificial Intelligence) 于12月10日公布了论文接收结果。中国科学院信息工程研究所第六研究室有15篇论文被AAAI2025录用。
AAAI由国际先进人工智能协会主办,是人工智能领域的顶级会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。AAAI2025共收到12,957篇投稿,其中3,032篇被接受,接受率为23.4%,计划于2025年02月25日-03月04日在美国费城召开。
下面是录用论文列表及介绍:
题目:
Relation Also Knows: Rethinking the Recall and Editing of Factual Associations in Auto-Regressive Transformer Language Models
论文作者:
刘曦雨,刘正宵,顾佴彬,林政,马万里,向继,王伟平
论文概述:
知识编辑的目标是修正大语言模型中的错误或过时的特定事实,通过调整模型参数来更新其内在知识。近年来,研究者开发了针对Transformer模型中事实存储和召回机制的方法,能够在定位到相关参数后进行精准编辑,这类方法已成为主流。然而,现有的编辑方法多依赖于以主实体为中心的知识召回,忽略了关系信息,导致“过度泛化”——即编辑某个事实后,影响了与该主实体相关的其他无关信息。为此,我们提出了一种新的基于关系的编辑方法RETS,它在编辑时同时考虑主实体和具体关系,从而避免对无关信息的影响。实验显示,RETS显著减少了过度泛化现象,并在其他性能指标上保持竞争力,实现了更加均衡的效果,挑战了传统以主实体为中心的编辑方式的主导地位。
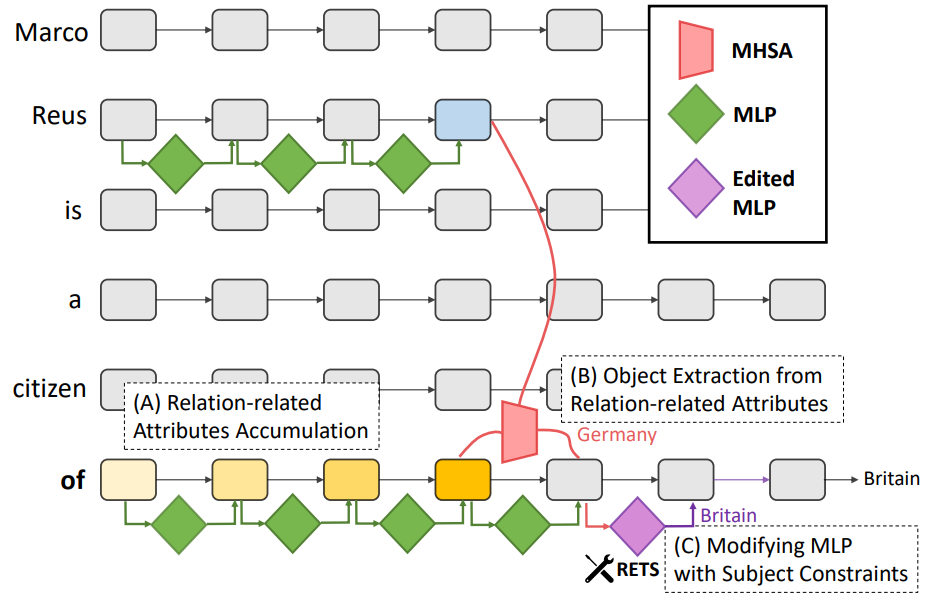
题目:
Trust-GRS: A Trustworthy Training Framework for Graph Neural Network Based Recommender Systems against Shilling Attacks
论文作者:
牟凌宇,刘正宵,朱祉同,林政
论文概述:
基于图神经网络(GNN)的推荐系统通过显式编码交互行为中的高阶邻居信息,能有效地捕获用户兴趣和物品特征,因此成为了主流推荐架构之一。最近的研究表明,与传统推荐架构相比,GNN的邻域聚合和对比学习机制使其更容易受到先令攻击的影响。攻击者通过向推荐系统的训练集中注入虚假用户配置文件,从而恶意操控目标物品的排名。尽管已有多种防御方法,但它们通常依赖先验知识,且难以同时应对多种攻击类型。基于此,本文提出了一种可信的两阶段GNN推荐系统训练框架(Trust-GRS),该框架对零知识场景下建模数据伪造的概率,设计出可信的邻域聚合和对比学习机制。通过在多个基准数据集上针对12种最先进的先令攻击的广泛实验,我们证明了Trust-GRS能够显著降低假数据对推荐结果的影响(最高达100%),同时保持原始推荐性能。由于无需依赖先验知识,Trust-GRS对现实世界的推荐平台具有重要的应用价值。
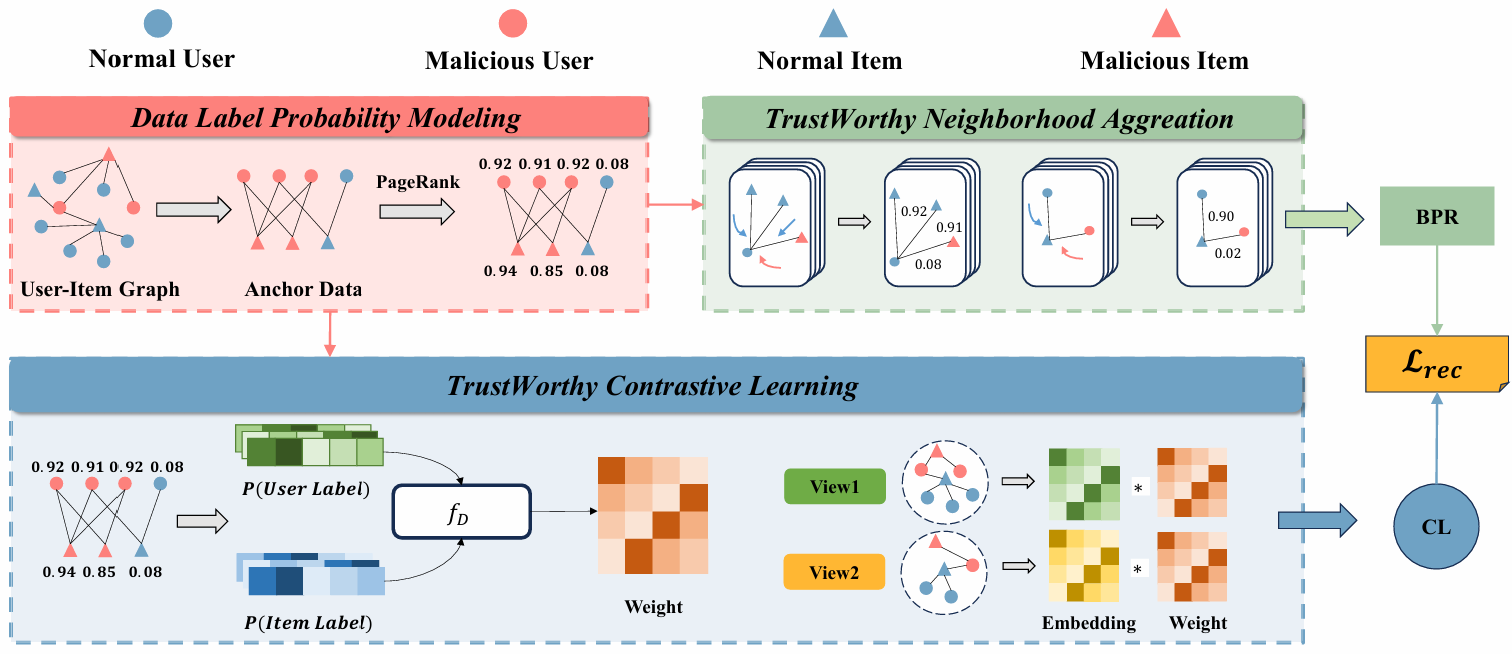
题目:
Multimodal Hypothetical Summary for Retrieval-based Multi-image Question Answering
论文作者:
李佩泽,佀庆一,付鹏,林政,王岩
论文概述:
基于检索的多图像问答任务涉及检索多个与问题相关的图像并根据这些图像以生成答案。常规的“先检索后回答”流程经常遭受级联错误,因为问答的训练目标未能优化检索阶段。为了解决这个问题,我们提出了一种新颖的方法,有效地将检索到的信息引入并引用到问答中。给定要检索的图像集,我们采用多模态大语言模型(视觉视角)和大语言模型(文本视角)来获得问题形式和描述形式的多模态假设综合(MHyS)。通过结合视觉和文本视角,MHyS 更具体地捕获图像内容并在检索中替换真实图像,转化为文本到文本的检索消除了模态差距并有助于改进检索。为了更好地将检索与问答结合使用,我们采用对比学习将查询(问题)与 MHyS 对齐。此外,我们提出了一种从粗到细的策略来计算句子级和单词级的相似度得分,以进一步增强检索并过滤掉不相关的细节。我们的方法在 RETVQA 上比最先进的方法实现了3.7%的提升,比CLIP 实现了14.5% 的改进。
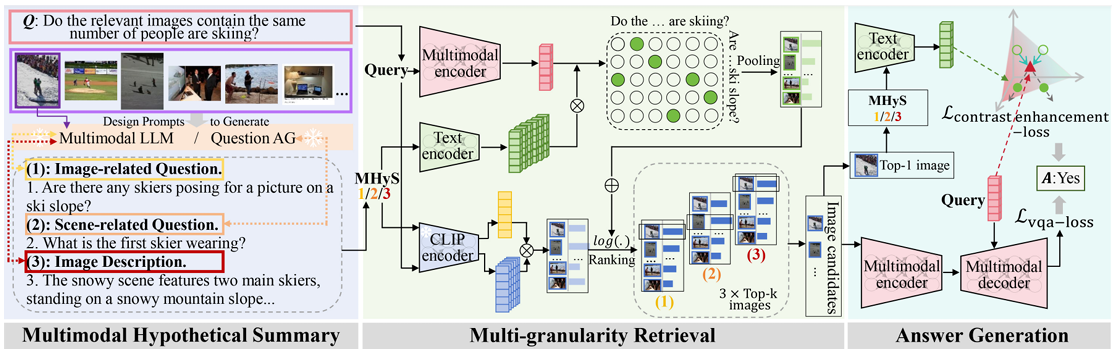
题目:
Union Is Strength! Unite the Power of LLMs and MLLMs for Chart Question Answering
论文作者:
刘佳朋,李亮,饶诗浩,高玺艳,关维鑫,李冰,马灿
论文概述:
图表问答(CQA)要求模型具备图表感知和推理能力。近期,在大型语言模型(LLMs)推动下的相关研究在图表问答领域占据了主导地位,包括利用认知能力更强的LLM对经过转换的图表(即表格)进行间接推理,以及利用感知范围更广的多模态大型语言模型(MLLMs)直接对图表进行感知。然而,图表到表格的转化存在信息的损失,限制了LLMs的认知能力;同时部分MLLMs在面临图表上的复杂推理时存在推理链断裂的可能。基于此,本文提出新的图表问答推理框架(Synergy),该框架将图表问答任务拆解为多个阶段,利用不同的信号在各个阶段中发挥LLMs和MLLMs的优势并规避它们的不足。实验显示,Synergy显著提升了单一大模型在图表问答任务上的表现,并展示出良好的灵活性,即使为MLLMs配备较小的LLMs,仍实现了相对于原始MLLMs直观性能提升。
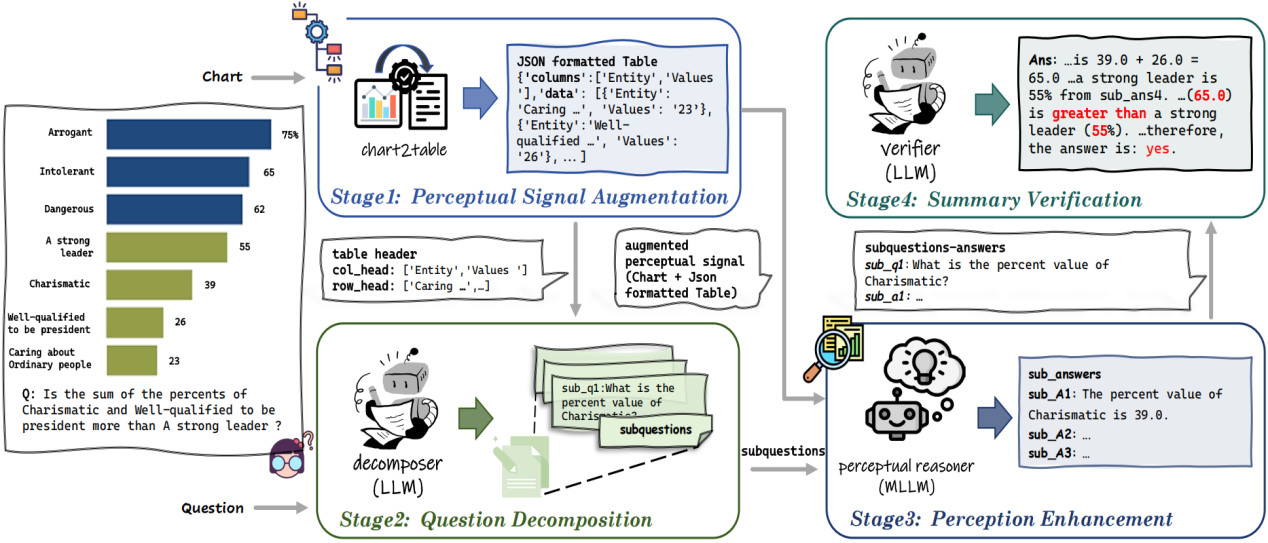
题目:
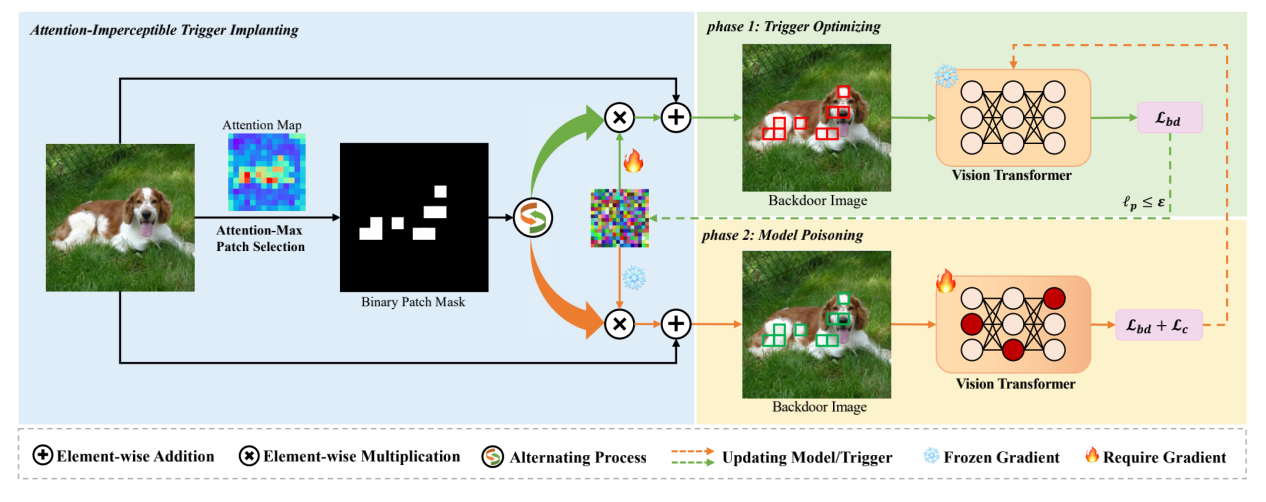
Attention-Imperceptible Backdoor Attacks on Vision Transformers
论文作者:
王植棽,王蕊,荆丽桦
论文概述:
随着Transformers成功从自然语言处理(NLP)领域过渡到计算机视觉(CV)领域,视觉Transformers(ViTs)在许多计算机视觉任务中取得了最先进的表现。然而,后门攻击作为深度学习中的一个重要威胁,也对ViT模型的安全性构成了风险。最近,已经提出了几种针对ViT中补丁级别自注意力机制的后门攻击方法,但这些方法在隐蔽性和对防御措施的鲁棒性方面相对较为简单,缺乏深入的研究。在本文中,我们探讨了注意力级别隐蔽性在ViT后门攻击中的关键作用,并提出了一种新的视觉Transformers注意力隐蔽后门攻击方法(AIBA)。在AIBA中,采用受限的对抗扰动作为触发器,以实现视觉隐蔽性。此外,触发器被设计为无缝地植入到图像的焦点区域,确保触发器能得到模型足够的关注而不在注意力层级上引起异常。在后门学习过程中,我们设计了一种高效的受限双层优化训练策略,利用隐蔽触发器将有效的后门植入受害模型。我们在多个数据集和ViT基准上评估了AIBA方法的有效性,并探讨了AIBA对当前ViT特定防御方法的鲁棒性。实验结果表明,我们的后门攻击方法能够成功地将强大且隐蔽的后门植入ViT模型。
题目:
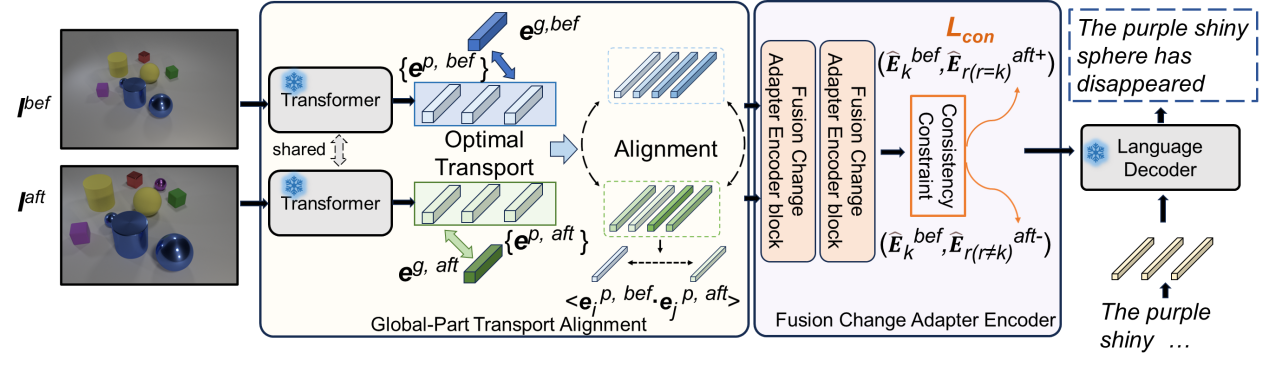
Revisiting Change Captioning from Self-supervised Global-Part Alignment
论文作者:
吕飞霄,王蕊,荆丽桦
论文概述:
图像变化描述的目标是捕捉两幅图像之间的内容差异,并用自然语言进行描述,其中的关键是如何从视角变化和图像整体结构等不稳定的伪变化中识别到稳定的内容变化。尽管现有许多方法将研究目标放在视角变化上,然而该类研究大都是基于简单的匹配或者针对微小的视角变化,对于视角变化带来的伪变化(例如物体的近大远小形变等)效果较差,从而使得对真实变化特征的识别不稳定。基于此,本论文提出了一种自监督的全局-部分对齐(SSGPA)方法,通过增强图像全局特征的构建过程来重新审视图像变化描述任务,使模型能够将视点等全局变化整合到局部变化中,通过对齐成对图像中的相应部位进一步判定变化区域,并引入适配器和相匹配的一致性损失对伪变化和真实变化进行了针对性的训练约束,最终生成包含真实变化的描述。本论文在多个常用数据集上对所提方法的多个模块进行了探讨,实验显示,所提出的SSGPA方法显著提高了图像变化描述的性能。
题目:
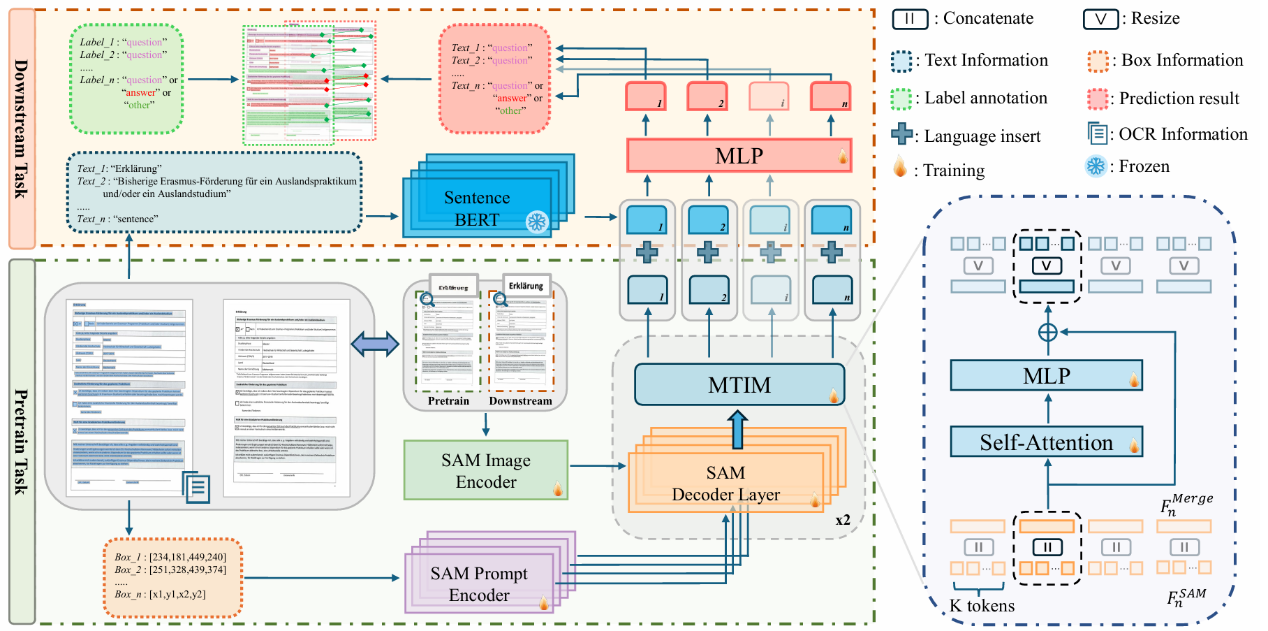
LDP: Generalizing to Multilingual Visual Information Extraction by Language Decoupled Pretraining
论文作者:
申化文,李庚洛,钟进文,周宇
论文概述:
目前的视觉文档信息抽取研究大多是单语种的(英语)。本文通过系统性的实验发现,在不同语言的图像中,视觉和布局模态具有不变性。如果从文档图像中解耦语言偏差,一个基于视觉和布局的模型可以实现优异的跨语言泛化能力。基于此,本文提出了一种简单但有效的多语言训练范式 LDP(Language Decoupled Pre-training),基于此训练的模型LDM(Language Decoupled Model)仅使用英语进行预训练,在多个语种的下游数据集中都取得了优异的表现。
题目:
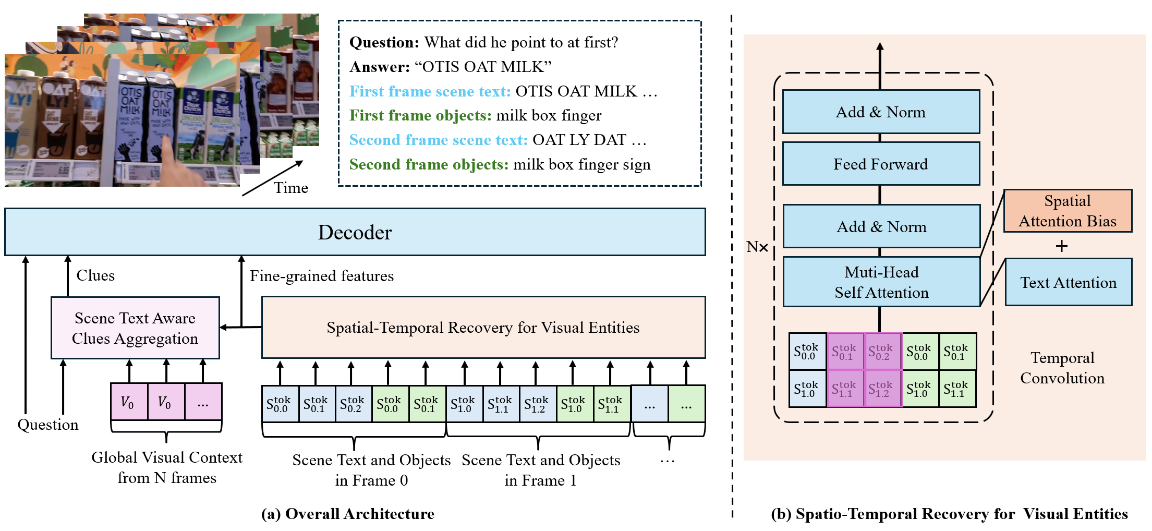
Track the Answer: Extending TextVQA from Image to Video with Spatio-Temporal Clues
论文作者:
张言,曾港艳,申化文,吴岱卿,周宇,马灿
论文概述:
视频场景文字视觉问答(Video TextVQA)是一项实用任务,旨在通过联合推理视频中的可视文字和视觉对象回答问题。受图像领域中,场景文字视觉问答(TextVQA)发展的启发,现有的Video TextVQA方法利用语言模型(如T5)处理包含丰富文本信息的多帧视频,并以自回归的方式生成答案。然而,视觉实体(包括场景文字和视觉对象)之间的时空关系容易被破坏,模型也容易受到无关信息的干扰,导致推理不合理和答案不准确。为了解决这些挑战,我们提出了TEA,进一步将生成式TextVQA框架从图像扩展到视频。TEA通过互补的方式恢复了时空关系,并结合了OCR感知的线索,以增强对问题的推理质量。在多个Video TextVQA数据集上的大量实验,验证了我们框架的有效性和泛化能力。TEA在性能上远超现有的TextVQA方法、视频语言预训练方法以及视频大模型。代码和数据集开源:https://github.com/zhangyan-ucas/TEA。
题目:
Arbitrary Reading Order Scene Text Spotter with Local Semantics Guidance
论文作者:
吕嘉昊,王威,杨东宝,钟进文,周宇
论文概述:
针对传统提取范式带来的阅读顺序缺失问题,本文提出了一个利用局部语义引导面向任意阅读顺序的场景文字提取器,能够自回归解码位置和局部语义指导的字符内容。通过设计了起始点定位和多尺度自适应注意力模块,在完成任意阅读顺序文字提取任务的基础上减轻计算开销。实验在多个数据集上验证本方法在任意阅读顺序的场景中有显著效果。
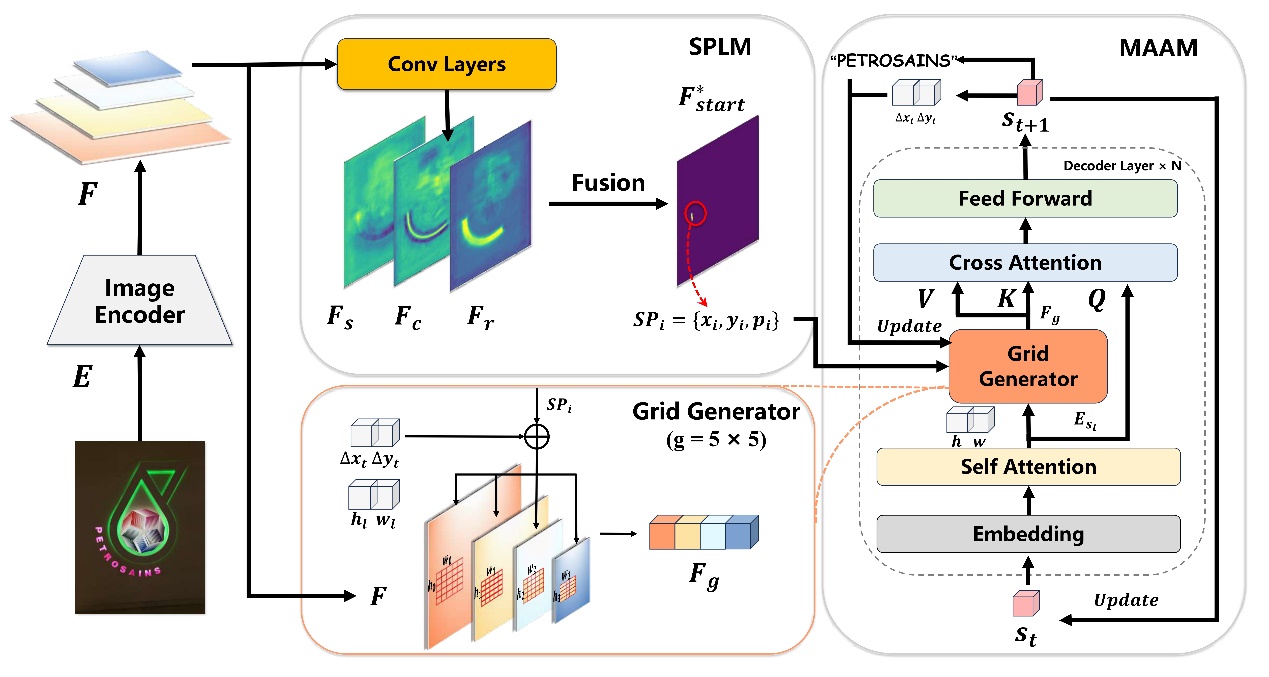
题目:
DCA: Dividing and Conquering Amnesia in Incremental Object Detection
论文作者:
张傲婷,杨东宝,刘畅,洪晓鹏,尚苗,周宇
论文概述:
现有的增量目标检测(IOD)方法通过改进知识蒸馏和样例重放取得了一定的成功,但遗忘的内在机制仍未得到充分探索。本文深入研究了其遗忘原因,发现了基于Transformer的增量检测中定位和识别之间存在遗忘不平衡,并提出一种分治健忘症策略,将基于Transformer的IOD重新设计为先定位后识别的过程,以保持和迁移定位能力,同时将预训练语言模型编码的语义知识有效嵌入在识别解码过程中,以减少识别特征的漂移。大量实验验证了本文方法有效缓解了增量目标检测中的灾难性遗忘,并且具有无需样例重放的优势。
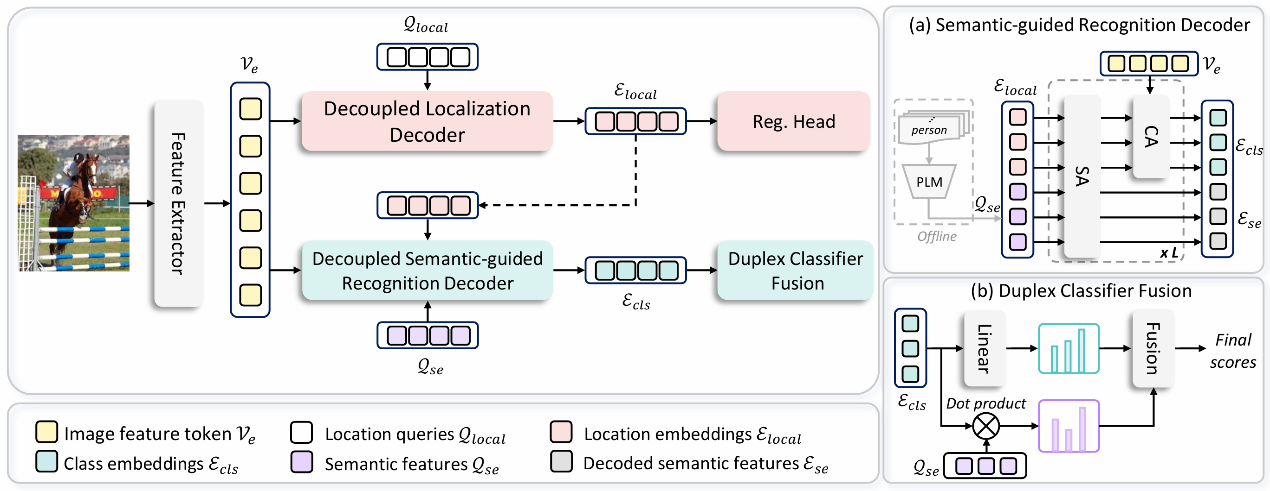
题目:
Specifying What You Know or Not for Multi-Label Class-Incremental Learning
论文作者:
张傲婷,杨东宝,刘畅,洪晓鹏,周宇
论文概述:
针对多标签类增量学习(MLCIL)中标签不完整带来学习目标冲突的问题,本文认为克服这一冲突的主要挑战在于模型无法明确区分已知和未知知识,这种模糊性阻碍了模型同时保留历史知识、掌握当前知识和为未来学习做准备的能力。本文旨在明确当前增量会话中已知和未知的知识以同时容纳历史、当前和未来知识,并提出了新框架HCP。HCP首先通过动态特征纯化和带分布先验的回忆增强来澄清已知知识,从而提高已知信息的精度和保留率。通过设计前瞻性知识挖掘来探索未知领域,为未来的学习预留特征空间。大量实验验证了此方法有效地缓解了 MLCIL 中的灾难性遗忘。
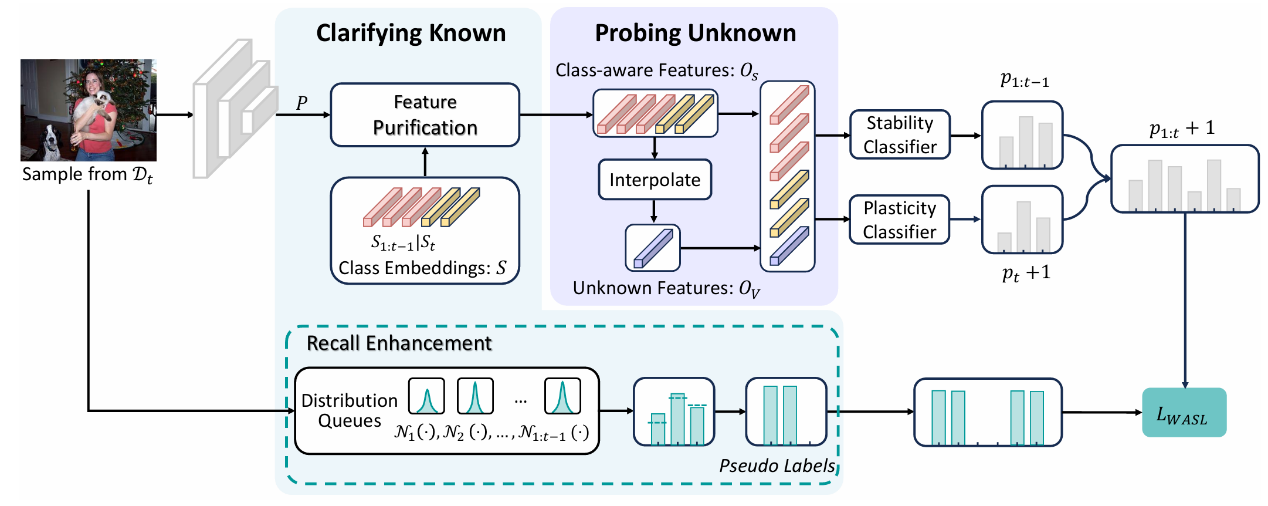
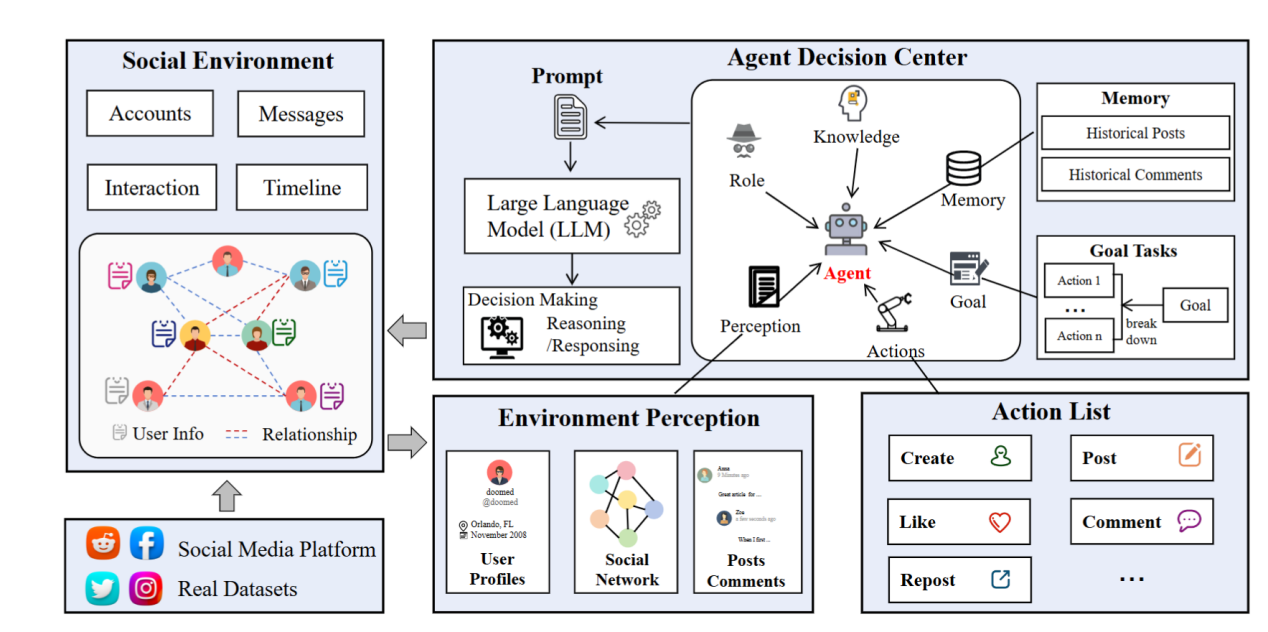
题目:
BotSim: LLM-Powered Malicious Social Botnet Simulation
论文作者:
乔博宇,李鲲,周薇,李世龙,逯倩倩,虎嵩林
论文概述:
Twitter、Reddit等社交媒体对全球交流至关重要,但大语言模型(LLM)技术的飞跃催生了高度智能的社交机器人。这些机器人能够精准模仿人类行为,散布大量虚假信息,给平台监管带来严峻挑战。为应对此威胁,本文创新性地提出BotSim—一个由LLM赋能的恶意社交机器人网络模拟系统。BotSim模拟真实社交网络的信息传播,构建了一个融合智能代理机器人与真实用户的虚拟环境。在模拟的时间线中,机器人能够进行自主发帖、评论等互动,还原了真实环境中信息流推荐和用户交互的场景。基于BotSim框架,本文进一步创建了高度拟人化、由LLM驱动的机器人数据集BotSim-24,并对其进行了一系列机器人检测策略的基准测试。实验结果显示,针对传统机器人数据集有效的方法在BotSim-24上表现较差,这凸显了迫切需要新的检测策略来解决这些先进机器人带来的网络安全威胁。
题目:
Task-level Distributionally Robust Optimization for Large Language Model-based Dense Retrieval
论文作者:
马广远,马永亮,伍星,苏振鹏,周明,虎嵩林
论文概述:
随着基础模型的改进、数据量的增加,以大模型(LLM)为基座的稠密检索(Dense Retrieval, DR)模型取得了优异的检索性能。大模型稠密检索(LLM-DR)基于大量异质的微调数据集进行训练,这些异质数据集的领域、语言、对称性等特征差异巨大。如何确定一个合适的数据分布或配比,使得这些数据集联合训练的性能达到更优,是提升大模型稠密检索性能的关键;现有研究中,关于大模型稠密检索的数据分布优化(Data Distributional Optimization)仍处于空白状态。如何决定使用哪些数据集、如何确定每个数据集使用的比例、以及如何用更少的数据达到更优的性能,常基于研究人员的经验性判断,通过反复的实验来解决这些问题。然而,我们不可能穷尽数据集联合训练的所有配比,这种经验性的试错空间巨大、代价较高,模型的鲁棒性不强,将不可避免地处于次优(Sub-optimal)状态,影响大模型稠密检索的性能表现;为了解决上述异质数据集联合训练的分布优化问题,我们提出了一种面向大模型稠密检索的任务级分布鲁棒优化(Task-level Distributionally Robust Optimization, tDRO)算法,端到端地学习鲁棒的数据分布。在大规模的开源文本检索训练集的联合训练场景中,本方法减少了30% 的数据集用量;并在大规模的单语、多语、跨语言检索基准中,显著提升了不同尺寸(500M, 1.8B, 4B, 7B, 8B)、不同基座(Qwen1.5, LLaMA3, Mistral-0.1)的大模型稠密检索的性能表现。

题目:
Enhancing Multi- hop Fact Verification with Structured Knowledge-Augmented Large Language Models
论文作者:
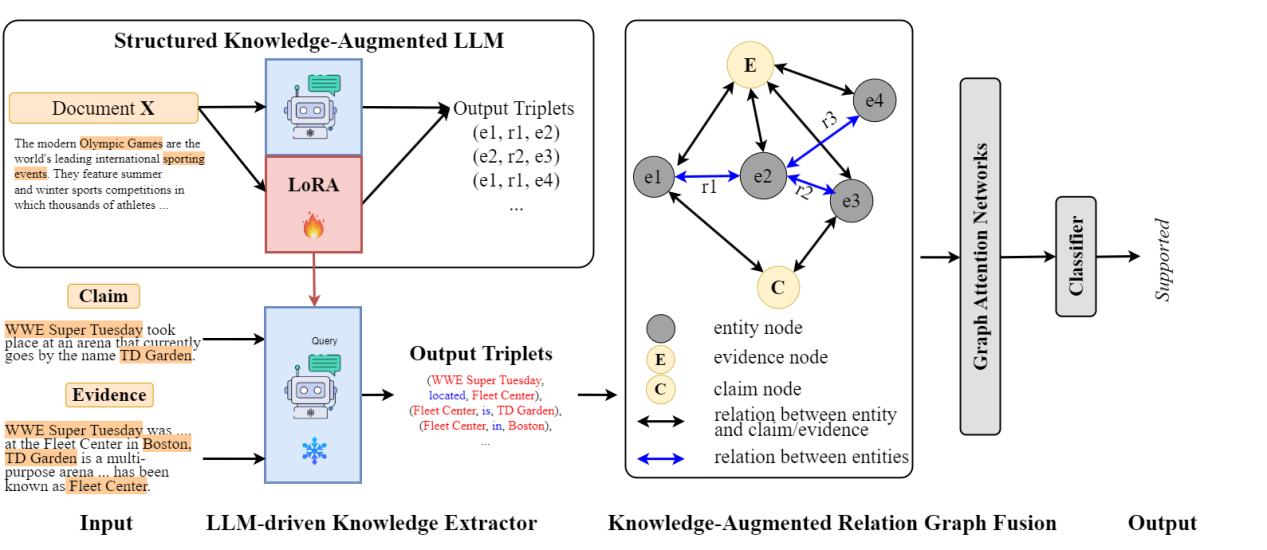
曹晗,卫玲蔚,周薇,虎嵩林
论文概述:
社交平台的迅速发展加剧了虚假、错误信息的传播,这促使了事实核查研究的发展。近期的研究倾向于利用语义特征将此问题作为单跳任务来解决。然而,在现实情况中,验证一个声明需要多条证据,这些证据之间存在复杂的内在逻辑和关系。近期的研究试图通过提高理解和推理能力来提升性能,但它们忽略了实体之间的关键关系,而这些关系有助于模型更好地理解并促进预测。为了强调关系的重要性,我们借助大型语言模型(LLMs),因为它们具有出色的理解能力。与将 LLM 用作预测器的其他方法不同,我们将其用作关系抽取器,因为实验结果表明它们在理解方面表现更佳而非推理。因此,为了解决上述挑战,我们提出了一种基于 LLM 的结构化知识增强网络(LLM-SKAN),用于多跳事实核查。具体来说,我们利用一个由大型语言模型驱动的知识提取器来捕获细粒度的信息,包括实体及其关系。此外,我们借助知识增强的关系图融合模块与每个结点进行全面交互,并学习更优的声明——证据表示。在四个常用数据集上的实验结果证明了我们模型的有效性。
题目:
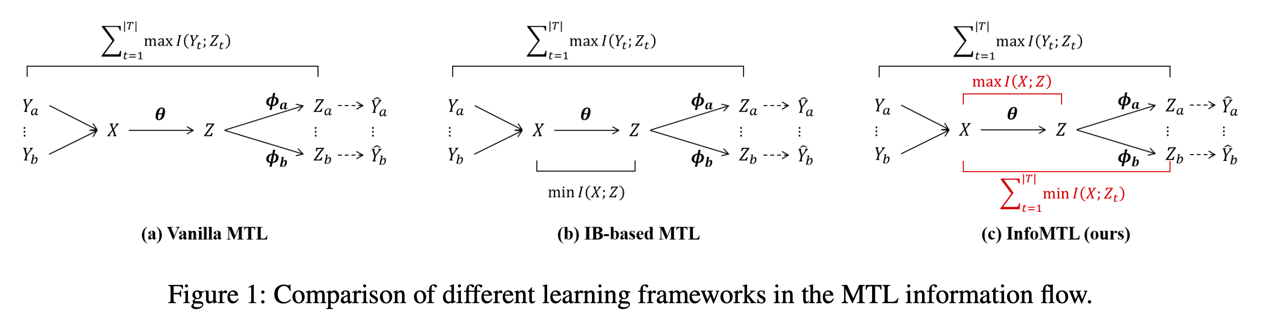
An Information-theoretic Multi-task Representation Learning Framework for Natural Language Understanding
论文作者:
胡斗,卫玲蔚,周薇,虎嵩林
论文概述:
本文提出了一种基于信息论的多任务表示学习框架(InfoMTL),用于提取噪声不变的、对所有任务均充分的潜在表示,以增强多任务范式下预训练语言模型的语言理解能力。该框架引入了两个学习准则:共享信息最大化 (SIMax) 和任务特定信息最小化 (TIMin)。SIMax 旨在促进共享表示保留所有任务所需的必要信息,而 TIMin 旨在消除每个任务特定的冗余信息。在六个分类基准的实验表明,InfoMTL 在不同网络骨架下的多任务表现均一致优于现有的多任务学习方法,且在数据受限和噪声场景具有显著优势。扩展实验表明,提出方法学习到的表示更加充分、数据高效且鲁棒。代码实现见 https://github.com/zerohd4869/InfoMTL。

 上一篇:生成式人工智能安全技术专项技术短期培训班暨中国科学院首届NLPer大会圆满落幕
上一篇:生成式人工智能安全技术专项技术短期培训班暨中国科学院首届NLPer大会圆满落幕 附件下载 :
附件下载 :