-
全部
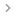

2026年3月22日至26日,第31届ACM编程语言与操作系统体系结构支持国际会议(ASPLOS 2026)在美国匹兹堡举行。作为计算机体系结构领域的顶级国际学术会议,ASPLOS长期聚焦芯片体系结构、编程语言与操作系统的交叉研究,汇聚全球学术界与工业界的最新代表性成果,是推动软硬件协同创新的重要国际学术平台。本届会议共收到投稿1048篇,经严格评审最终录用152篇,录用率14.5%。
大会期间,来自全球学术界和产业界的专家学者围绕计算机体系结构及相关领域的最新研究进展进行了广泛而深入的交流,系统探讨了体系结构未来发展的重要挑战与前沿方向。中国科学院信息工程研究所网络空间安全防御全国重点实验室侯锐研究员团队在会上报告了题为《Maverick: Rethinking TFHE Bootstrapping on GPUs via Algorithm-Hardware Co-Design》的最新研究成果。该论文由王志伟副研究员担任第一作者,赵路坦研究员、侯锐研究员担任共同通讯作者。具体介绍如下:
全同态加密(Fully Homomorphic Encryption, FHE)是一种能够在密文状态下直接执行任意计算的密码技术,为隐私保护计算提供了重要的技术路径。然而,复杂的密码学运算流程与高昂的计算开销,使其在实际部署与大规模应用中仍面临显著挑战。尽管硬件加速被普遍视为提升FHE执行效率的关键途径,但单纯依赖底层算力扩展,难以有效突破算法结构与执行流程所固有的性能瓶颈。因此,面向FHE的高效加速方法,特别是算法与硬件协同优化的系统性设计,已成为当前学术界持续关注的研究重点。
该论文提出了面向 GPU 的 TFHE 自举加速方案 Maverick,从算法与硬件协同设计角度对TFHE自举流程进行了系统优化。在算法层面,研究通过将测试向量由“预加载”改为“后注入”,重构了传统盲旋转过程。在硬件层面,研究提出部分域 NTT 变换策略,以阶段感知方式提前终止 NTT,并通过重新划分算子边界,将部分计算转移至后续算子中,实现 EP 各算子之间的工作负载均衡(见图2)。实验结果表明,Maverick 在可编程自举任务上相较现有最优 CPU 和 GPU 基线分别实现了 331.2 倍和 3.4 倍的加速,在电路自举任务上相较 CPU 基线最高实现了 108.5 倍的性能提升。该成果不仅显著刷新了通用 GPU 平台上的 TFHE 自举性能水平,也表明算法–硬件协同设计是突破全同态加密效率瓶颈、推动隐私计算核心技术迈向实用化的重要方向。
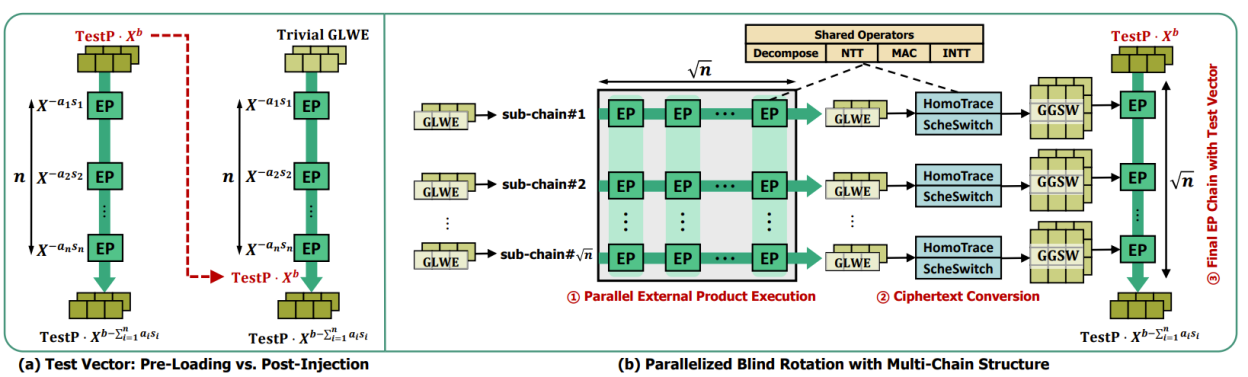
图1. 并行化盲旋转设计
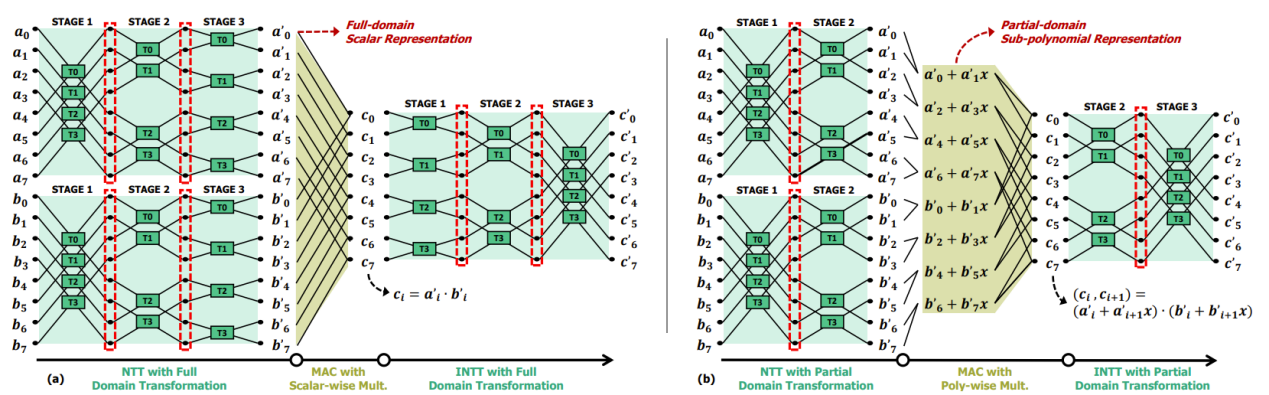
图3. (a)全域NTT转换与点乘MAC (b)部分域NTT转换与多项式级MAC
论文信息:Zhiwei Wang, Haoqi He, Lutan Zhao*, Qingyun Niu, Dan Meng, Rui Hou*. Maverick: Rethinking TFHE Bootstrapping on GPUs via Algorithm-Hardware Co-Design. ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS) 2026.
论文链接:https://dl.acm.org/doi/10.1145/3779212.3790186.
附件下载:

